

Introduction
As we demonstrate in second part of this article, we was able to improve search results, but we talked also on how to return suggestion to typo in searching.
In this article I am going to use Levenshtein Distance Algorithm.
Levenshtein Algorithm calculates the distance between 2 input strings. If we have 2 equal strings like “A” and “A” we get distance 0, but if we have “A” and “B” we will get 1. The Algorithm iterate the process for both strings input
length and sum up the difference between strings. At the end of the Algorithm we will have a final number of distance. The greater distance is the less chance both strings are related. This Algorithm does not intelligence, so if we search for word like job we can get word like Jacob with distance 3 as relative word.
There is a punch of recommendation to fine tune the search, but that requires a search engine strategy to define the search roles. In our case, we just made a standard implementation of the Algorithm. We have also added a percentage string length measurement to reach best possible results, but that will still not fix Job vs Jakob case, but will improve search results. In case you need to make it intelligible, you need to use other algorithms like NLP, Machine Learning, use a word dictionary etc. I have asked a question regarding this on stackoverflow you can read it here.
Example
We imagine to search word ”test” but for some reason we type ”tset”.
The image below describes how does the Algorithm calculate the distance. In our case the two mentioned words has a distance of 2
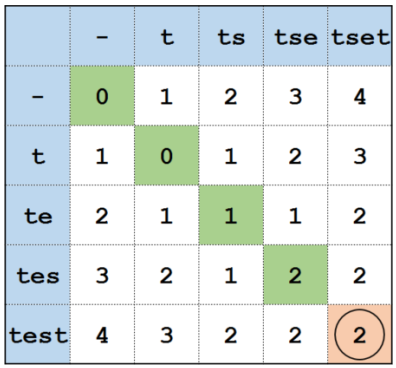
Distance calculation matrix example
Implementation
So All that explanation, lets do have a look at our Levenstein Algorithm using Dynamic Programming approach:
private int Compute(string inputWord, string checkWord)
{
int n = inputWord.Length;
int m = checkWord.Length;
if (n == 0)
{
return m;
}
if (m == 0)
{
return n;
}
_wordMatrix = new int[n + 1, m + 1];
for (int i = 0; i <= n; i++)
{
_wordMatrix[i, 0] = i;
}
for (int j = 0; j <= m; j++)
{
_wordMatrix[0, j] = j;
}
for (int i = 1; i <= n; i++)
{
for (int j = 1; j <= m; j++)
{
if (inputWord[i - 1] == checkWord[j - 1])
{
_wordMatrix[i, j] = _wordMatrix[i - 1, j - 1];
}
else
{
int minimum = int.MaxValue;
if ((_wordMatrix[i - 1, j]) + 1 < minimum)
{
minimum = (_wordMatrix[i - 1, j]) + 1;
}
if ((_wordMatrix[i, j - 1]) + 1 < minimum)
{
minimum = (_wordMatrix[i, j - 1]) + 1;
}
if ((_wordMatrix[i - 1, j - 1]) + 1 < minimum)
{
minimum = (_wordMatrix[i - 1, j - 1]) + 1;
}
_wordMatrix[i, j] = minimum;
}
}
}
return _wordMatrix[inputWord.Length, checkWord.Length];
}
So now if we pass a word like “dnemark” to this algorithm, we will get a suggestion like “denmark” as you can see in my example below:

Complexity analysis
I have had 2 choices to build Levenshtein Algorithm, by using Recursion or
Dynamic Programming. To find out which solution was better, I made a little Analysis on both approaches.
- Recursion
Regarding to on-line resources1 using recursion have a complexity of O(2n). - Dynamic Programming
Dynamic Programming that means we memorize the strings in array. We need to iterate through our two string input in nested loop. That gives m * n time which is O(n2) worst case. (m and n = string length for each input)
Mathematically n2 is much faster than 2n, therefore our implementation choice was Dynamic Programming approach.
I have put all code and data source together for all Search Engine series in my GitHub Blog Example Repo, enjoy.
Conclusion
In this article we have learned to about Levenstein Distance algorithm and how it is used by providing searching example.
We have also analysis the complexity of Levenstein with recursive approach and Dynamic Programming approach.
Finally we demonstrated how Levenstein code looks like in C#.
In future, I will make an article about Lucene search feature in C#. I am also considering adding Frequency Index feature or adding front-end UI feature for this search engine, if you think it is a good idea or you like to have such article, please let me know in comments.